[GCP] Cloud Dataflow
<구글클라우드 뽀개기>책을 참고한 내용입니다.
- Cloud Dataflow는 배치 및 스트림 모드로 데이터를 변환하고 처리할 수 있는 완전 관리형 서비스이다. Apache Beam과 같은 프로젝트로, 무제한에 가까운 용량을 이용해 대규모 데이터 처리를 할 수 있다. 아파치빔 SKD를 통한 자바/파이선 API를 통해 간단하게 파이프라인을 개발할 수 있다.
- 지원하는 언어 : Java, Python, Go
- Dataflow vs Dataproc
- 둘은 모두 동일하게 데이터 처리에 사용할 수 있다.
- 단, Dataflow는 Apache Beam기반, Dataproc은 Apache Hadoop/Spark기반이며
- Dataflow는 서버리스고 Dataproc은 DevOps를 사용하고
- Dataflow는 기존에 러거시 없이 새로 접근할 때 적합하고 Dataproc은 Apache 빅데이터 생태계(Hadoop Echo System)에 적합하다.
- Dataflow 흐름 및 구성요소
- Input >transform> PCollection > transform > PCollection >transform> Output
- PCollection
Dataflow pipeline이 작동하는 분산 데이터세트를 나타낸다. 데이터를 저장하는 개념으로 한 번 생성되면 그 데이터는 수정이 불가능하다. 내용을 변경하려면 새로운 PCollection을 생성해야한다.
특징 :
1) 요소유형 : PCollection의 요소는 모두 동일한 유형이어야하며, 분산처리를 위해서는 각 개별 요소가 바이트 문자열로 인코딩 가능해야함.
2) 불변성 : PCollection은 변경이 불가하다.
3) 무작위 접근 : PColleciton은 개별 요소에 대한 무작위 액세스를 지원하지 않는다.
4) 크기와 경계 : 제한되지 않는 PCollection은 Pubsub/Kafka같은 데이터 소스로 만들고, 고정크기의 데이터세트는 보통 파일이나 배체 데이터 소스로 만든다.
5) 요소 타임스탬프 : PCollection은 각 요소에 타임스탬프가 찍힌다.
- Unbounded Data(스트리밍 데이터) 처리
Unbounded Data(스트리밍 데이터)는 데이터가 끊이지 않고 들어오기 때문에 결과를 내보내야하는 타이밍을 잡기가 어렵다. 따라서 이를 시간단위로 끊어서 처리하는 것을 '윈도윙(Windowing)'이라고 한다.
1) Fixed Window : 고정된 크기의 시간을 가지는 윈도우 (ex. 10분단위의 Window)
2) Sliding Window : 다른 윈도우들과 중첩되는 윈도우 (ex:. 10분단위의 윈도우/5분단위의 윈도우 간격-새로운 윈도우가 생기는 시간간격)
3) Session Window : 데이터가 들어오면 윈도우가 시작되고, 세젼 종료시간까지 데이터가 들어오지 않으면, 윈도우를 종료하고 새로운 데이터가 들어올 때 다시 새로운 윈도우를 생성한다.
- Trigger
윈도우가 끝나야지 그것에 대한 결과값을 볼 수 있다. 만약 윈도우의 길이가 1시간이라면 그 동안의 데이터를 실시간으로 볼 수 가 없기 때문에 실시간 데이터분석이라고 할 수 없다. 이 때 윈도우가 끝나기전에 중간계산값들을 보여주는 것이 Trigger이다.
종류)
Time trigger : 특정 이벤트 시간에 작동 (5분마다 or 윈도우 시작할 때마다 or 윈도우 끝날 때 마다)
Element count trigger : 데이터의 개수를 기반으로 작동
Punctuation tirgger : 특정 데이터가 들어오는 순간에 작동
Composite trigger : 여러가지 trigger를 조합한 형태
실습
1. GCP검색창에 Dataflow API 사용설정/관리 선택
2. Python에서 apache-beam을 사용하기 위한 명령어 입력 (pip install apache-beam)

3. Python구축환경에서 dataflow에 연결

실행시키면 작업이 새로 생성되어있는 것을 확인할 수 있다.

** 'Map' >> beam.Map(lambda (w, c)): "%s: %d" % (w, c) \
파이선 3버전에서는 위의 코드 중 (w, c)형태의 튜플을 지원하지 않아서 에러가 뜸. 그래서 빼버렸다.
4. dataflow 화면에서 확인

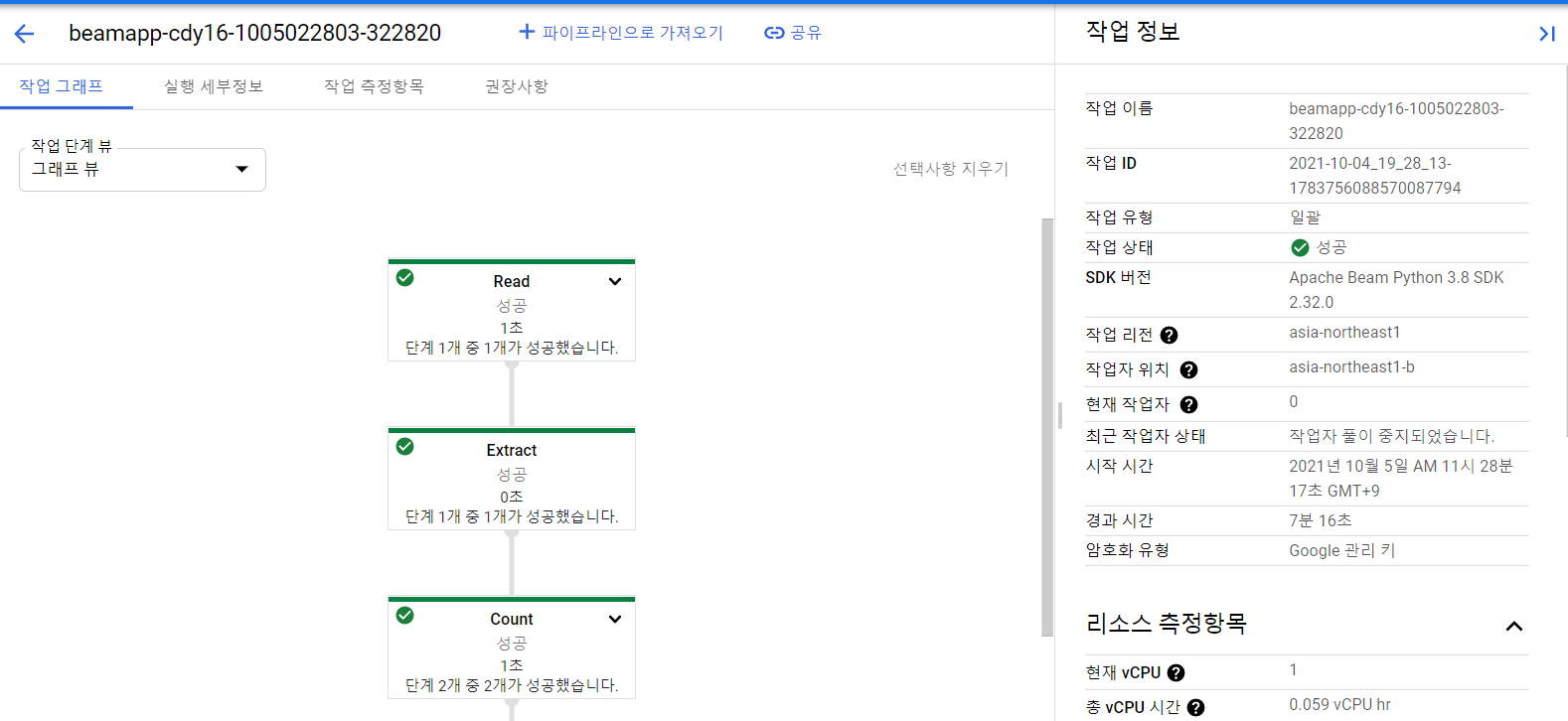
5. 데이터 스토리지 버킷에 결과값을 받기위한 txt파일 생성코드가 실행되었음을 알 수 있다.

6. output.txt확인
